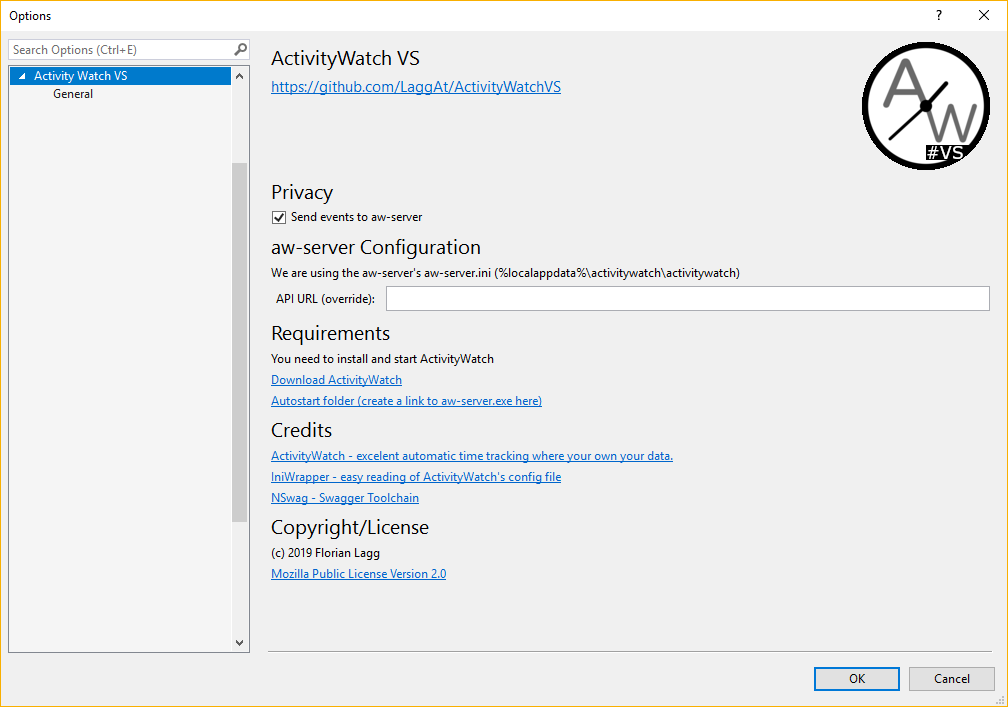
Hi, as mentioned in another thread I’m developing an watcher for Visual Studio as Plugin.
It’s already working well, but I have some questions how things are handled best:
- Events: currently I’m cumulating similar events and set the duration. Is it better to push events as heartbeats and with duration=0, or should I cumulate it? I think cumulating should be better, as I really know when the user is working on the code and could provide better detail, but maybe I get your opinions on it.
- aw-server.ini: I found this file in the local %AppData% folder. I want to use it to show the user 1) if AW is installed, and 2) if it is running (using the port config in there). When is this file created (Installation, first run) and does it always end up in that folder?
- (this one isn’t related to this watcher, but I want it to happen) I’ve found some documentation on sync - I really want this - how far is the planning/development for this?
That’s it for now, as soon as I am ready I’ll release it to Github or so, and publish it as VS plugin.
Kind regards,
Florian.